La qualité et la fiabilité des données figurent depuis toujours parmi les priorités stratégiques des organisations. Dans un contexte où les volumes d’informations explosent et les sources se multiplient, garantir l’exactitude et l’accessibilité des données devient un défi majeur. L’intégration de l’intelligence artificielle dans les processus décisionnels renforce davantage cette exigence : les modèles d’IA les plus sophistiqués restent inefficaces sans données cohérentes, gouvernées et continuellement mises à jour.
Dans les faits, de nombreuses organisations se heurtent à des silos d’information cloisonnés, des architectures difficiles à maintenir et des coûts qui s’envolent. Les équipes métiers comme data se retrouvent alors confrontées à des délais allongés et à une capacité d’analyse limitée.
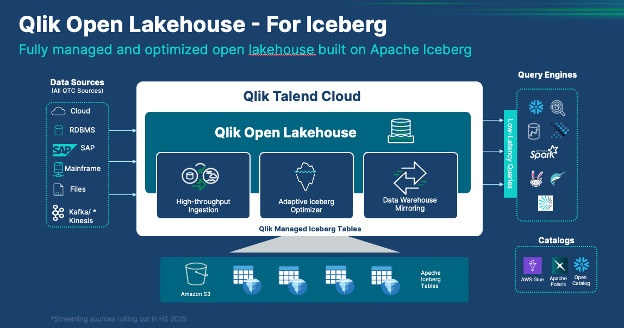
C’est dans ce contexte que Qlik Open Lakehouse prend tout son sens. Intégré à Qlik Talend Cloud, cette architecture data nouvelle génération vise à unifier la gestion des données au sein d’un environnement ouvert, conciliant flexibilité, performance analytique et gouvernance.
Dans cet article nous verrons comment cette solution unifie vos données via Apache Iceberg et les bénéfices qu’elle apporte à votre organisation.
Du data warehouse au Data Lakehouse : comprendre l’évolution
Pour mesurer pleinement l’apport de Qlik Open Lakehouse, il est essentiel de comprendre l’évolution qui a mené au concept de Data Lakehouse et ce qui le distingue de ses prédécesseurs.
Le data warehouse
Pendant longtemps, les entreprises se sont appuyées sur le Data Warehouse, un entrepôt de données structuré et performant, idéal pour le reporting classique et l’analyse décisionnelle. Cette approche offrait fiabilité et rapidité d’exécution pour les requêtes analytiques. Toutefois, face à l’explosion des volumes de données et à la diversité croissante des formats, le Data Warehouse a montré ses limites : rigidité dans l’évolution des schémas, coûts élevés de stockage et difficulté à intégrer des données non structurées.
Le data Lake
Le Data Lake est apparu comme réponse à ces contraintes, promettant un stockage massif et flexible de données brutes à moindre coût. Capable d’accueillir tous types de formats (structurés, semi-structurés, non structurés), il offrait une grande liberté. Malheureusement, sans gouvernance stricte, ces lacs se sont souvent transformés en marécages ingérables, compliquant l’exploitation et l’analyse des données.
Le data Lakehouse : le meilleur des deux mondes
Le Data Lakehouse réconcilie ces deux approches. Il combine la flexibilité et le faible coût du Data Lake avec la structure et les capacités transactionnelles du Data Warehouse. Cette architecture hybride permet d’exécuter des analyses avancées et de déployer des modèles d’IA sur l’ensemble des données, qu’elles soient structurées ou non, au sein d’une plateforme unifiée.
Qlik Open Lakehouse : qu’est-ce que c’est exactement ?
Qlik Open Lakehouse se positionne comme une réponse complète et moderne aux défis du Lakehouse. Il ne s’agit pas d’un simple outil de stockage, mais d’une solution entièrement managée qui orchestre l’ensemble du cycle de vie de la donnée : ingestion en temps réel, transformation, gouvernance et analytique. L’architecture est conçue pour être “ouverte”, ce qui signifie qu’elle élimine le verrouillage propriétaire (vendor lock-in) souvent imposé par les fournisseurs cloud. Vos données restent accessibles et peuvent être exploitées par différents moteurs d’analyse comme Snowflake, Databricks ou Amazon Athena, sans duplication ni migration complexe. Elle permet aux entreprises de conserver la maîtrise de leurs données tout en bénéficiant d’une plateforme entièrement managée
L’un des atouts majeurs de cette solution réside dans son automatisation intelligente. En effet, grâce à l’optimiseur adaptatif (Adaptive Iceberg Optimizer), Qlik Open Lakehouse gère les tâches de maintenance technique en arrière-plan, garantissant ainsi que les tables de données restent performantes sans nécessiter d’intervention manuelle complexe de la part des ingénieurs de données.
Apache Iceberg : le moteur qui change la donne
Au cœur de cette architecture bat un moteur puissant : Apache Iceberg. Il s’agit d’un format de table open source conçu pour les vastes ensembles de données analytiques. Contrairement aux simples fichiers stockés dans un data Lake classique, Iceberg apporte des fonctionnalités dignes d’une base de données relationnelle, notamment les transactions ACID (Atomicité, Cohérence, Isolation, Durabilité). Cela garantit que les données ne sont jamais corrompues lors des opérations d’écriture ou de modification concurrentes. De plus, Iceberg permet l’évolution des schémas sans casser les pipelines existants et offre la fonctionnalité de “Time Travel”, qui permet de revenir à une version antérieure des données pour des audits ou des corrections. En intégrant nativement ce standard Qlik Open Lakehouse offre une structure robuste et interopérable, capable de dialoguer avec n’importe quel moteur de requête compatible.
Les bénéfices concrets de Qlik Open Lakehouse pour votre entreprise
Au-delà de ses capacités techniques, l’adoption de Qlik Open Lakehouse génère des bénéfices tangibles qui impactent directement la performance et la compétitivité des organisations :
Un moteur d’optimisation intelligent
Qlik Open Lakehouse intègre l’Adaptive Iceberg Optimizer, un moteur qui gère automatiquement l’ensemble des tâches techniques complexes :
- Compression intelligente des fichiers pour réduire drastiquement les coûts de stockage
- Organisation dynamique des données pour accélérer l’exécution des requêtes
- Nettoyage automatique des données obsolètes et des fichiers orphelins
- Ajustement automatique des ressources selon les besoins, adaptant la puissance de calcul en fonction du volume de données
Selon Qlik, cette optimisation continue permet d’améliorer les performances des requêtes de 2,5 à 5 fois et de réduire les coûts de stockage jusqu’à 50%, le tout sans intervention manuelle (source : Qlik Blog). Les performances restent ainsi stables, même lorsque les volumes de données augmentent considérablement.
Une intégration complète dans Qlik Talend Cloud
Les entreprises bénéficient d’un environnement unifié pour orchestrer l’ensemble du cycle de vie de leurs données :
- Capturer les données en temps réel depuis leurs applications métiers grâce à la technologie Change Data Capture (CDC)
- Appliquer des règles de qualité et de fiabilité pour garantir l’exactitude des informations
- Tracer l’origine et les transformations des données grâce à une gouvernance centralisée
- Connecter directement ces données à des outils d’analyse et de visualisation comme Qlik Sense
L’ensemble forme une chaîne de traitement continue et fluide, de la collecte des données jusqu’à leur valorisation dans des tableaux de bord ou des modèles d’intelligence artificielle.
Ouverture et interopérabilité
Vos données, stockées au format Apache Iceberg, restent accessibles par divers moteurs analytiques comme Snowflake, Amazon Athena, Databricks, Apache Spark ou Trino. Cette approche ouverte vous laisse libre de choisir les outils les plus adaptés à chaque cas d’usage, sans duplication de données ni dépendance technologique.
Scalabilité et agilité
Étant cloud-native, la solution s’adapte automatiquement aux pics d’activité sans dégradation de performance, absorbant la croissance des volumes de données sans nécessiter de reconfiguration manuelle. La capacité d’ingestion en temps réel réduit drastiquement le time-to-insight, permettant aux décideurs de réagir immédiatement aux évolutions du marché.
Tableau récapitulatif : Qlik Open Lakehouse en un coup d’œil
Pour visualiser rapidement comment cette solution transforme votre architecture de données, voici une synthèse des fonctionnalités clés et de leur impact direct sur votre activité.

La transition vers une architecture Data Lakehouse n’est plus une option pour les entreprises qui souhaitent rester compétitives à l’ère de l’IA, c’est une nécessité stratégique. Qlik Open Lakehouse démocratise cette technologie puissante en supprimant la complexité technique généralement associée à Apache Iceberg, tout en garantissant performance et ouverture.
Pour aller plus loin sur ce sujet, accédez gratuitement au replay de notre webinaire dédié.
Si vous souhaitez évaluer comment cette architecture peut s’intégrer dans votre environnement actuel ou réaliser un audit de vos pipelines de données, nos experts sont à votre disposition.
Contactez-nous dès aujourd’hui pour transformer votre patrimoine de données en un véritable levier de croissance.